

3D Printering: Trinamic TMC2130 Stepper Motor Drivers
Adjust the phase current, crank up the microstepping, and forget about it — that’s what most people want out of a stepper motor driver IC. Although they power most of our CNC machines and 3D printers, as monolithic solutions to “make it spin”, we don’t often pay much attention to them.
In this article, I’ll be looking at the Trinamic TMC2130 stepper motor driver, one that comes with more bells and whistles than you might ever need. On the one hand, this driver can be configured through its SPI interface to suit virtually any application that employs a stepper motor. On the other hand, you can also write directly to the coil current registers and expand the scope of applicability far beyond motors.

Last month, we took a closer look at microstepping on common stepper driver ICs, but left out the ones that we actually want to use: the smart ones. Trinamic provides some of the smartest stepper motor drivers on the market, and since the German hacker store Watterott released their SilentStepStick breakout boards for the TMC2100 and TMC2130, they are also setting a new standard for DIY 3D printers, mills and pick-and-place robots. I recently acquired a set of both of them for my Prusa i3 3D printer, and the TMC2130 with its SPI configuration interface really caught my attention.
The TMC2130 SilentStepStick should not be confused with the — far more popular — TMC2100 variant. As the name suggests, it comes as a StepStick-compatible breakout board, and just like it’s famous sibling, features a Trinamic IC on the bottom side of the little PCB. Several vias and copper spills conduct heat away from the IC’s center pad, allowing a heatsink on the top side to effectively cool the driver.

However, unlike the TMC2100, this one won’t let your motors spin right away. You’ve got two options: Hard-wire it in stand-alone mode, which practically turns it into a TMC2100, or hook up to its SPI-interface and dial in if you want your stepper motor shaken or stirred. In fact, plentiful configuration registers make the TMC2130 an extremely hackable chip, so I’m not even thinking about bridging that solder jumper on the SilentStepStick’s bottom side that activates the stand-alone mode.
First Steps
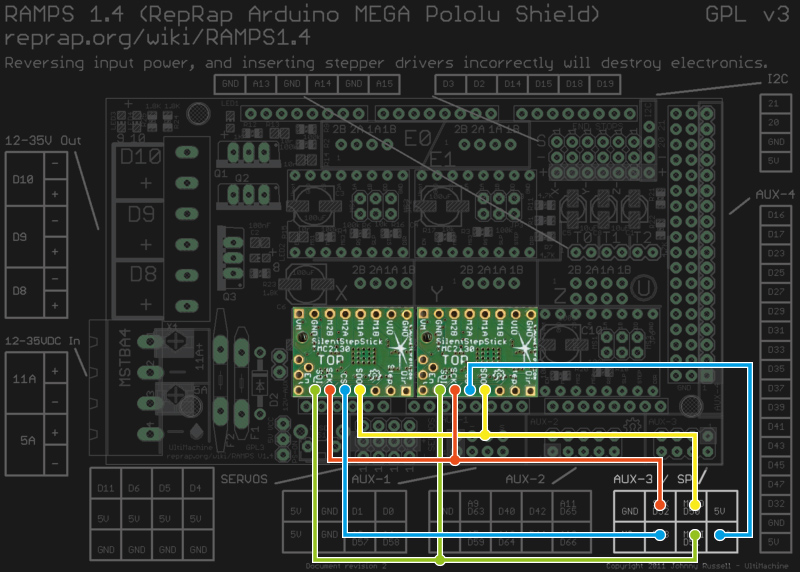
As said, before the driver does anything, it wants to be configured, and it’s worth mentioning that all configuration registers are naturally volatile, so if I want to use them in my 3D printer, I need to configure them as part of the printers startup routine.
The RAMPS 1.4 on my 3D printer breaks out the hardware SPI interface of the underlying Arduino through its AUX3 pin header, along with two additional digital pins (D53 and D49), which I used for the cable select signals. After crimping a cable to connect two TMC2130’s to the AUX3 header, I could start digging into the software part.
Watterott provides an example sketch, which writes a basic configuration to the driver’s registers and spins an attached stepper motor. Great stuff, but the datasheet describes 23 configuration registers waiting to be finely tuned, and 8 more to read diagnosis and status data from. So, I wrote a little Arduino library that would make the numerous configuration parameters available in a more practical way. From there, I could just include my library into the Marlin-RC7 3D printer firmware I’m using. Luckily, the current Marlin release candidate already features support for TMC26X drivers, so I could reuse some of its code to put together a Marlin fork that includes 59 of the TMC2130’s parameters in its define-based configuration files. And then, I could take the little buddies out for a spin.

Taking Them For A Spin
With the hardware set up and the software working as supposed, I ran a few sanity tests: toggling parameters on and off and checking how the driver’s behavior changes during printing. Since the TMC2130 let’s you tune almost everything it’s doing, that’s a good first step that helps to eliminate some variables and picking others that are worth a deeper look. Most of the settings can be changed on the fly and mid-print, however, not all parameters can actually be safely changed while the motors are running.

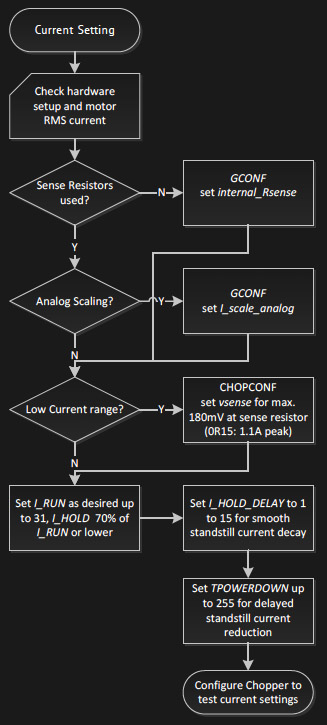
To actually tune the drivers for a certain application, Trinamic provides a quick start guide in the datasheet, as well as detailed information on each parameter, and on how they interact. Basically, the first step is adjusting the RMS coil current by using the onboard potentiometer on the SilentStepSticks. Then, we need to chose the analog input pin as a current scaling reference to actually make use of the potentiometer. The mentioned library lets me do this through a simple method:
myStepper.set_I_scale_analog(1); // 0: internal, 1: AIN
The running and holding current are the first real parameter that should be tuned, with the running current typically at the desired maximum current, and the holding current at 70% of this value. The delay between a stillstand and the transition from running current to holding current can be adjusted between 0 and 4 seconds, and for now, I set it to 4 seconds, practically disabling the current reduction while the 3D printer is running. The three values share one write-only register, so the corresponding method call looks like this:
myStepper.set_IHOLD_IRUN(22,31,5); // [0-31],[0-31],[0-5]
and sets the running current to 100% (≙ 31), the holding current to about 70% of this value (≙ 22), and the delay between the two to 4 seconds (≙ 5).
I want torque, so I can leave stealthChop disabled. The datasheet suggests some starting values for configuring the chopper’s off time and the comparator’s blank time settings, but since it’s a key tradeoff between switching noise and torque, it makes sense to iterate through other values as well. The library methods for the two values look like this:
myStepper.set_tbl(1); // [0-3] myStepper.set_toff(8); // [0-15]
And finally, I need to pick a microstepping resolution and choose if I want to make use of the 256 microstep interpolation feature, covered later in this article:
myStepper.set_mres(32); // {1,2,4,8,16,32,64,128,256}
myStepper.set_intpol(1); // 0: off, 1: interpolate
I have yet to walk through the entire tuning procedure, which includes monitoring the coil current on the scope and eliminating distortions in the zero crossing, but I’m getting a clue of the driver’s potential.
Juice
It’s maximum continuous RMS current of about 1.2 A per coil (at least in the QFN package on the SilentStepSticks) lets it look like a low-current driver, inferior to the common A4988 and DRV8825. In practice, it outperforms both of them by making intelligent use of a 2.5 A peak current margin. This gives it more than enough torque for 3D printing. I wouldn’t recommend pushing them over 0.9 A RMS though since the IC will momentarily pull more current if it needs more. For SilentStepStick users, that’s a Vref of 0.88 V. Through the SPI-interface, you can choose how much current you want to send through the motor coils when it’s spinning, and when it’s idling. You can choose after how many seconds it will start to decrease the current to a lower holding current when the motor is in standstill, and then to an even lower idling current. And, of course, you can also set it to squeeze out the maximum juice for everything.
Shifting The Gears
Where it starts getting interesting are settings like the high-velocity mode. Above a configurable velocity threshold, the driver offers you to automatically switch the chopper to a faster decay time to squeeze out some extra speed. You can also literally shift the gears by letting the driver internally switch from microstepping to full-step mode once it’s up to speed.
Microstepping
Choosing a finer microstepping resolution smoothens the stepper’s movement, reduces vibrations and sometimes even increases the positioning accuracy. However, it also multiplies the load on the microcontroller, which has to churn out 16, 32 or 256 times more step pulses per second. The TMC2130 lets you pick an input resolution between 1 and 256 microsteps per full-step, and then gives you the option of interpolating the output resolution to 256 microsteps. This allows for smooth operation even on increasingly retro 8-bit AVR motion controllers, which cannot deliver high step frequencies. Also, by configuring the TMC2130’s interface to double-edge step pulses, you can at least double the step frequency at almost no cost. Given that the modern IC still features the classic step/direction interface and even an enable pin, those few additional features actually make it a sweet drop-in upgrade for less-recent CNC and 3D printer electronics.
Noise Reduction
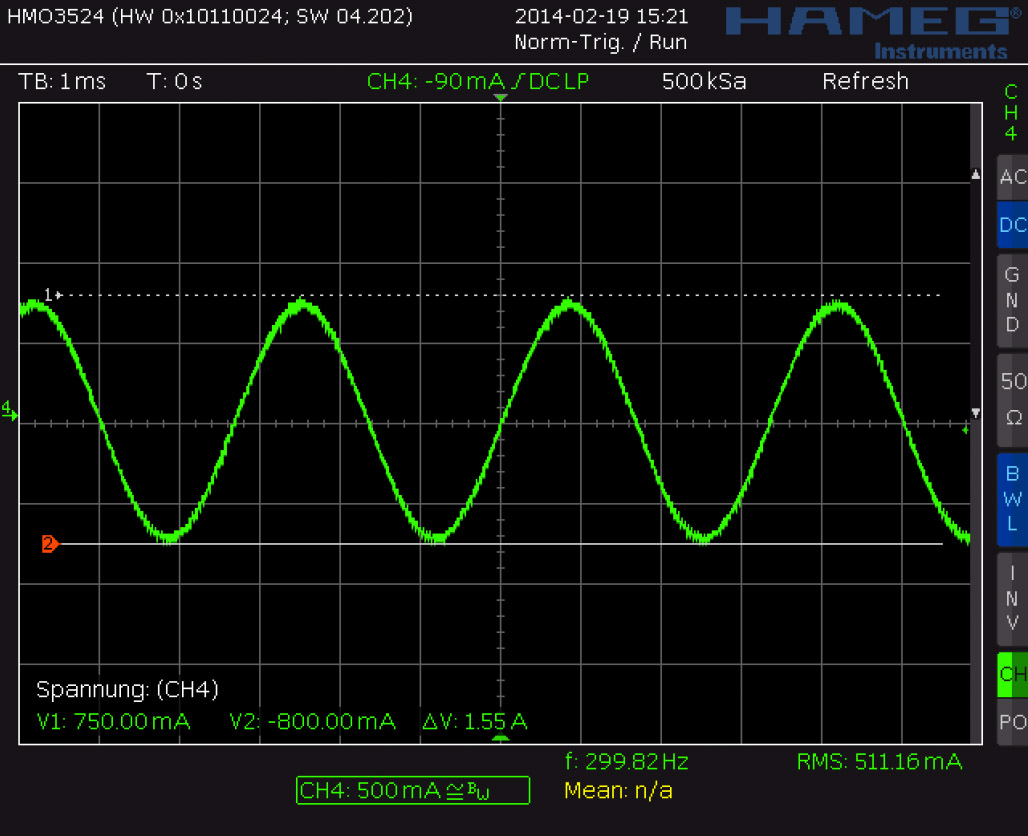
Just like the TMC2100, the TMC2130 features two efficient and silent drive modes: spreadCycle, and stealthChop. The former delivers high torque at relatively low noise emissions, the latter one is almost inaudible but delivers a dramatically reduced torque. The flexible IC also allows you to tweak the chopper yourself to find the right balance between torque, noise, and efficiency for your application. One of the more noteworthy options in this regard is the possibility of randomizing the chopper’s off time. Since most of the audible noise is released due to dubstep the chopper busily switching the stepper motor’s coils, this option spreads the noise over a wider frequency range to subjectively silence the stepper motor.
Stall Detection
The TMC2130 notices when the motor is stalled and losing steps by measuring the motor’s back EMF. Along the way, it counts missed steps, allowing the controller to compensate for otherwise irreversible step-loss. It’s also a great way to react to obstacles rather than running into them full-force and, of course, the feature can be used as an axis endstop. Trinamic calls this feature StallGuard, and just like anything else in this motor driver, it’s highly configurable.
Direct Mode
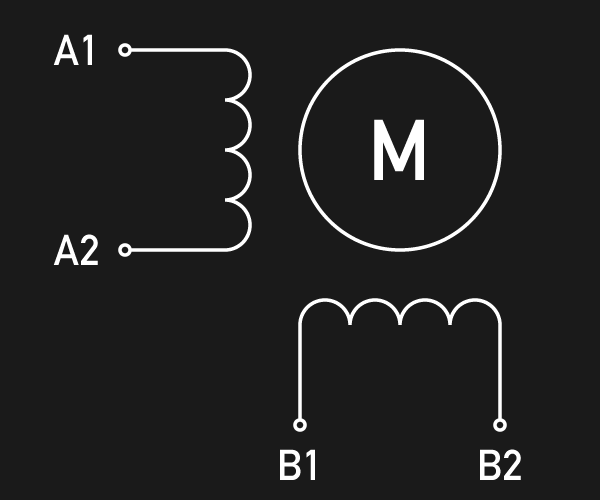 Instead of letting the motor driver handle everything for you, you can also choose the direct mode. This mode practically turns the driver into a two-channel, bipolar constant-current source with SPI interface. You can still use it as a motor driver, but the possibilities reach far beyond that. It’s worth mentioning that the datasheet might be a bit confusing here, and the corresponding XDIRECT register actually accepts two signed 9 bit integers (not 8 bit) for each coil and operates as expected within a numeric range of, naturally, ± 254 (not ± 255) to vary the current between ± Imax/RMS..
Instead of letting the motor driver handle everything for you, you can also choose the direct mode. This mode practically turns the driver into a two-channel, bipolar constant-current source with SPI interface. You can still use it as a motor driver, but the possibilities reach far beyond that. It’s worth mentioning that the datasheet might be a bit confusing here, and the corresponding XDIRECT register actually accepts two signed 9 bit integers (not 8 bit) for each coil and operates as expected within a numeric range of, naturally, ± 254 (not ± 255) to vary the current between ± Imax/RMS..
The Takeaway
About half a year after the release of Watterott’s breakout board, the potential of smarter stepper motor drivers piqued the curiosity of the 3D printing community, but not much has happened in terms of implementation. Admittedly, it takes some effort to get them running. If you’re still busy dialing in the temperature on your 3D printer, you surely don’t want to add a few dozen new variables, but if you’re keen on getting the best out of it, the TMC2130 has a lot to offer: low-noise printing, high-speed printing, print interrupt on failure and recovery from lost steps. Because the driver IC is so hackable, it’s clearly intended to be tuned in to accommodate specific applications. Throwing it on a general purpose test bench probably won’t yield meaningful, general purpose results.
I hope you enjoyed taking a look at a smarter-than-usual stepper motor driver, as one of the new frontiers of DIY 3D printing, and as an interesting component with many other applications. If you’re thinking about experimenting with this IC or breakout board in your 3D printer, feel free to try my Marlin fork to get started. If you’re building something entirely different, the underlying Arduino library will help you out. Who else is using this part? I’ll be glad to hear about your ideas, applications, and experiences in the comments!
Filed under: 3d Printer hacks, Hackaday Columns






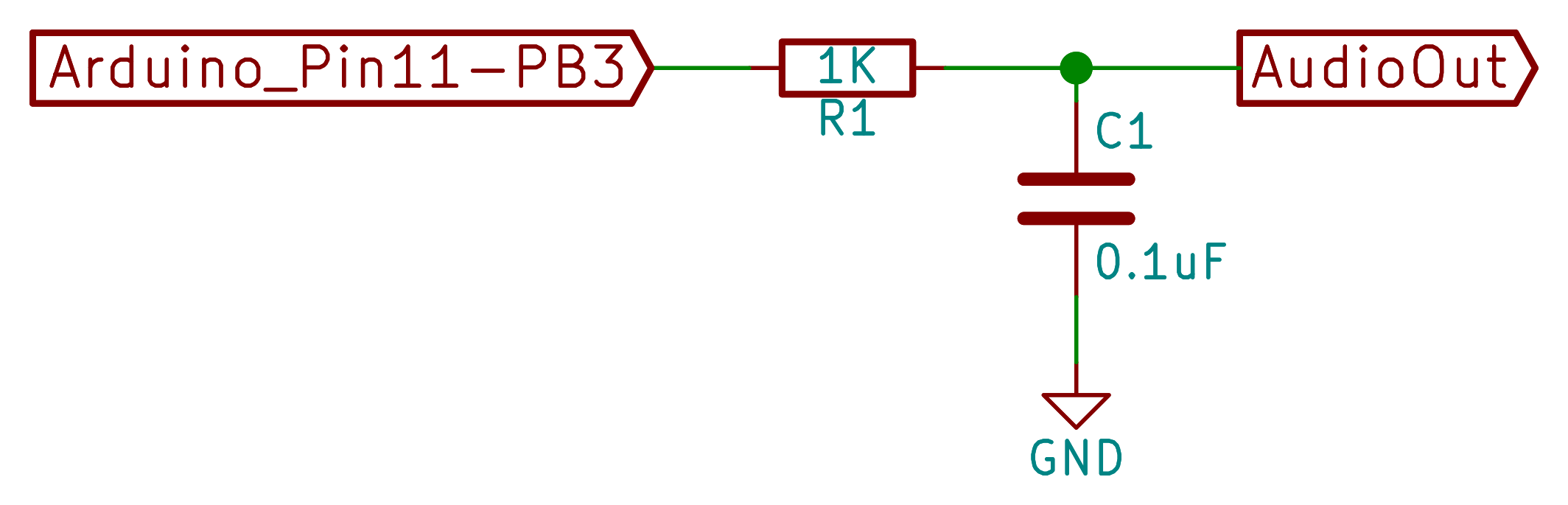


















 running a calculus function on an Arduino presents a seemingly impossible scenario. In this article, we’re going to explore the idea of using derivative like techniques with a microcontroller. Let us be reminded that the derivative provides an instantaneous rate of change. Getting an instantaneous rate of change when the function is known is easy. However, when you’re working with a microcontroller and varying analog data without a known function, it’s not so easy. Our goal will be to get an average rate of change of the data. And since a microcontroller is many orders of magnitude faster than the rate of change of the incoming data, we can calculate the average rate of change over very small time intervals. Our work will be based on the fact that the average rate of change and instantaneous rate of change are the same over short time intervals.
running a calculus function on an Arduino presents a seemingly impossible scenario. In this article, we’re going to explore the idea of using derivative like techniques with a microcontroller. Let us be reminded that the derivative provides an instantaneous rate of change. Getting an instantaneous rate of change when the function is known is easy. However, when you’re working with a microcontroller and varying analog data without a known function, it’s not so easy. Our goal will be to get an average rate of change of the data. And since a microcontroller is many orders of magnitude faster than the rate of change of the incoming data, we can calculate the average rate of change over very small time intervals. Our work will be based on the fact that the average rate of change and instantaneous rate of change are the same over short time intervals.
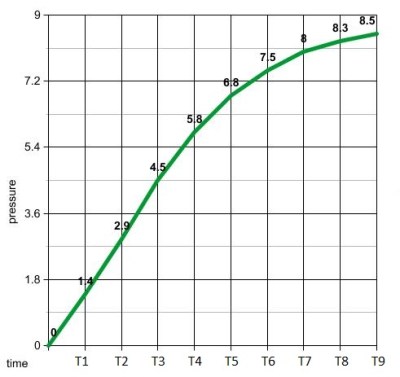
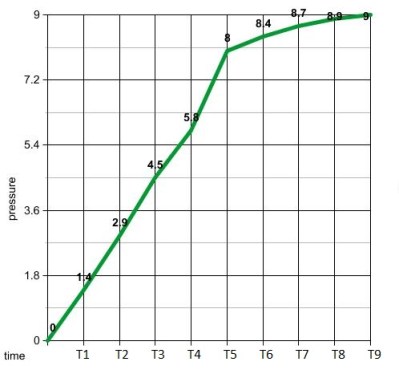


 This code experiment uses a Sparkfun Redbot setup for line following. This is a two wheeled robot with 3 optical sensors to detect the line and an I2C accelerometer to sense bumping into objects. The computer is a Sparkfun Redbot Mainboard which is compatible with the Arduino Uno but provides a much different layout and includes a motor driver IC.
This code experiment uses a Sparkfun Redbot setup for line following. This is a two wheeled robot with 3 optical sensors to detect the line and an I2C accelerometer to sense bumping into objects. The computer is a Sparkfun Redbot Mainboard which is compatible with the Arduino Uno but provides a much different layout and includes a motor driver IC.









{kind=link}