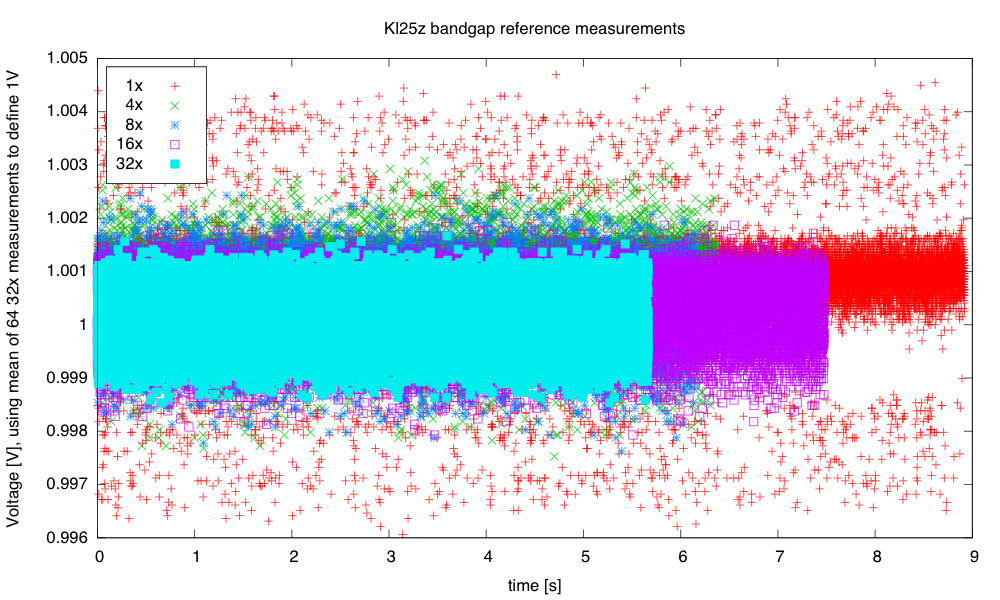
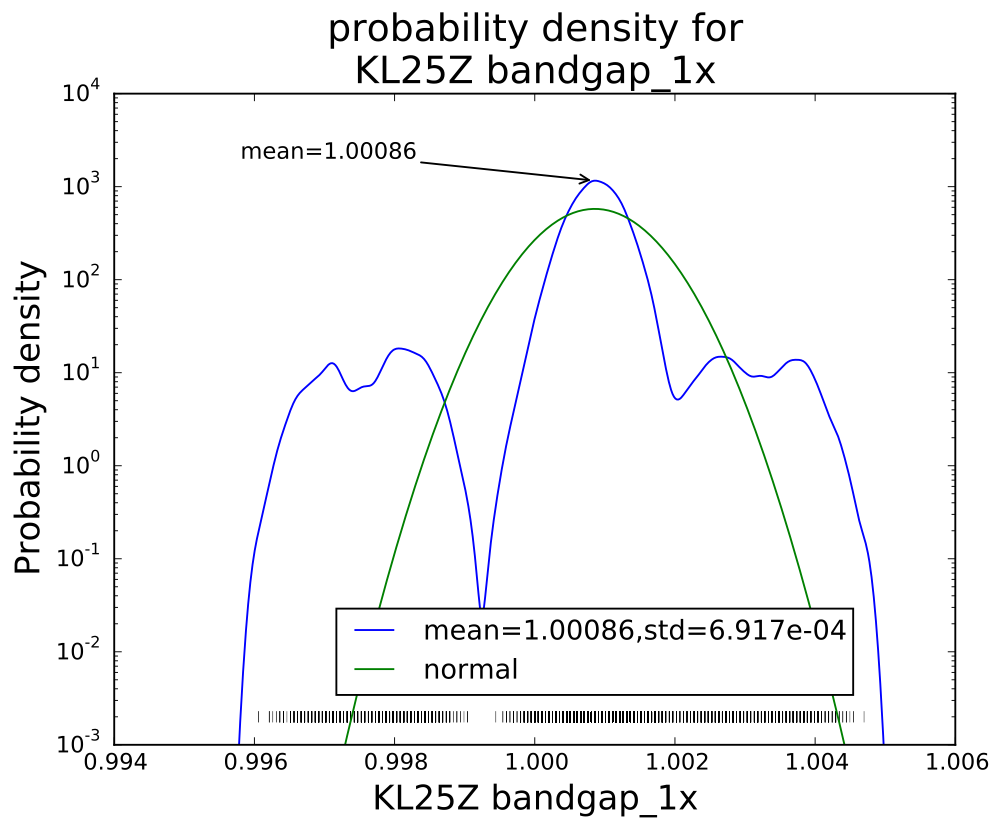
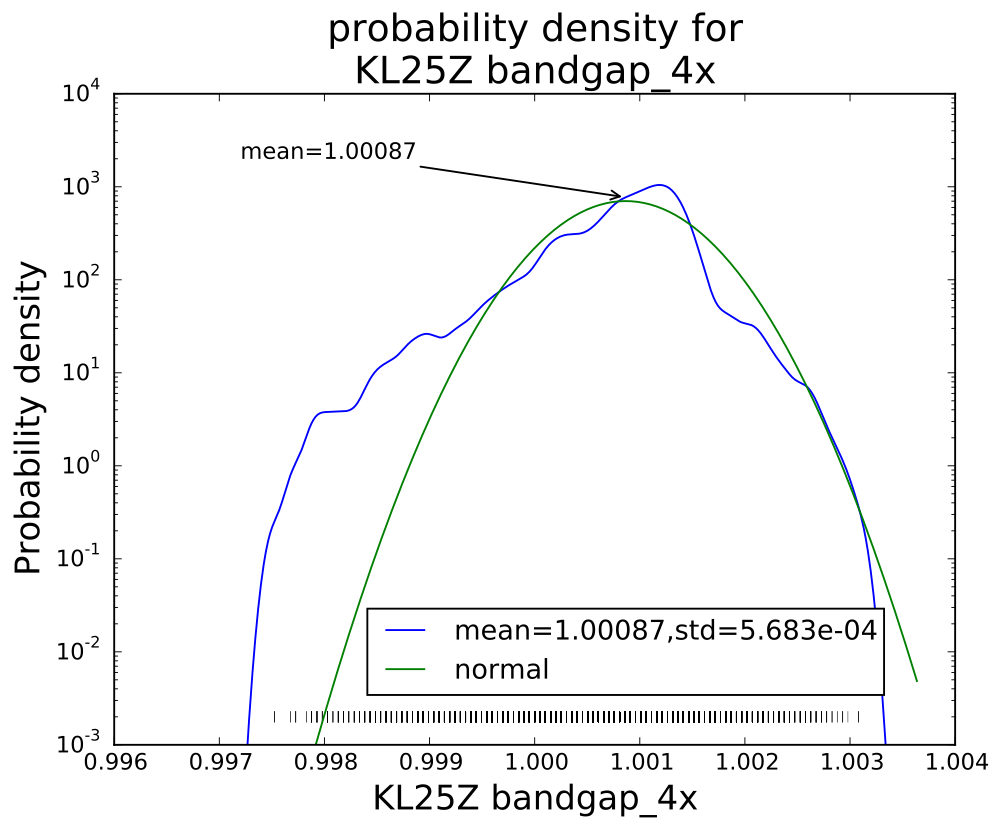
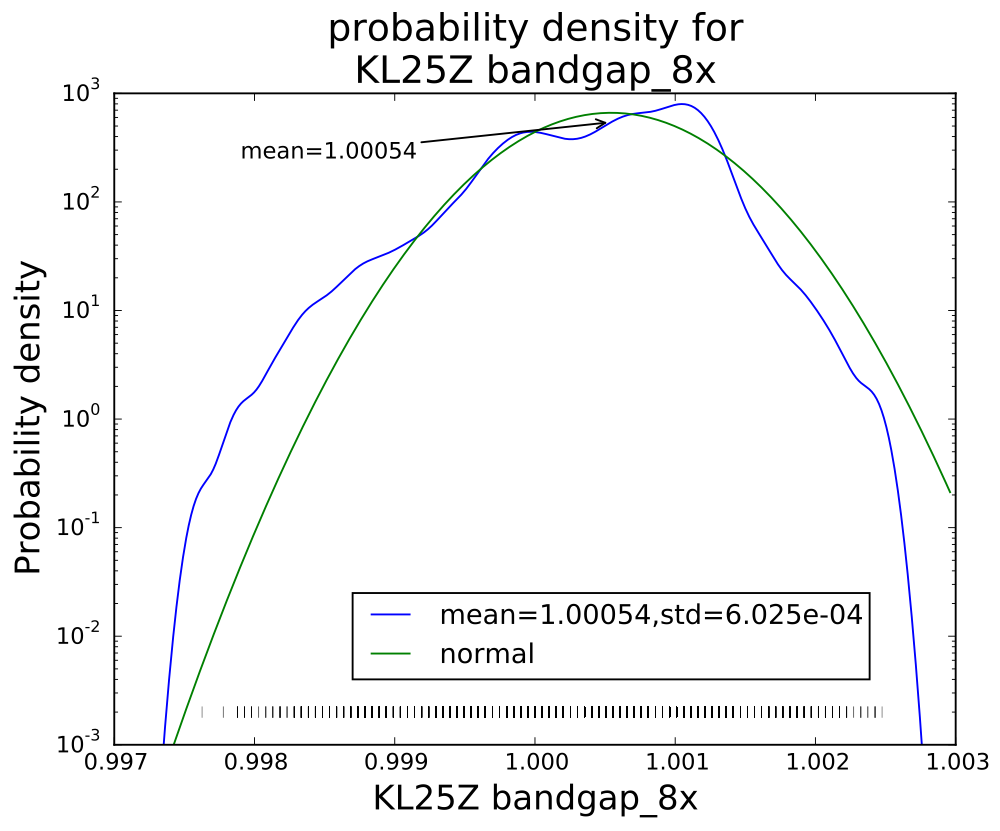
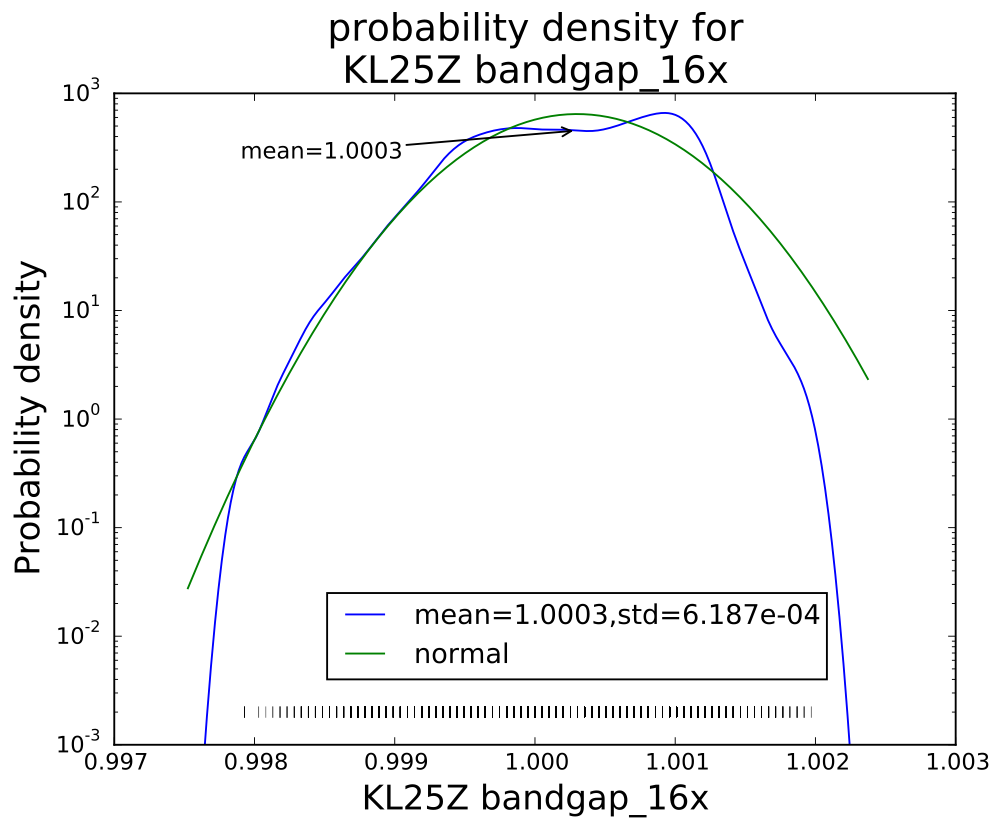
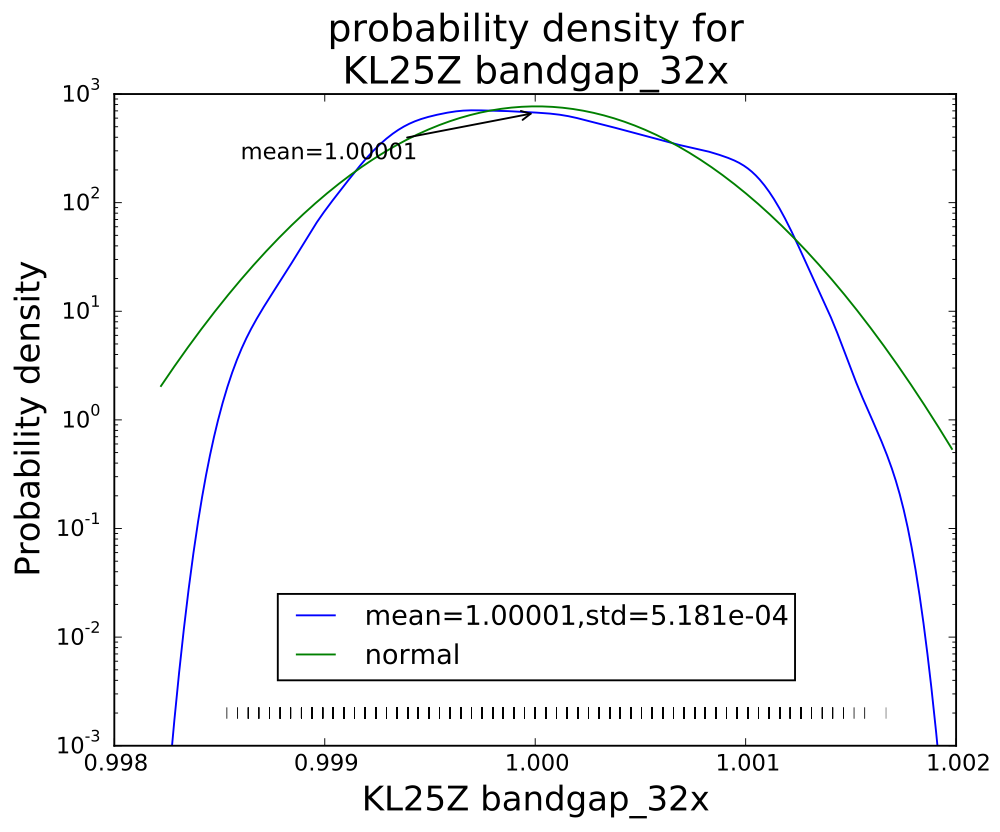
PteroDAQ v0.2b1 released!
For the past couple of years, I’ve been using the PteroDAQ data acquisition system that my son wrote for the KL25Z board (a second-generation system, replacing the earlier Arduino Data Logger he wrote). Over the past week, he has been transferring the project to me, and together we did a lot of debugging and enhancements.
Today, we tested the code on the ancient Windows 7 machines in the circuits lab at UCSC (we only have Mac OS 10 and Linux at home), and decided it was ready for a beta release.
The new code is way better than the old code! Here are a few of the bigger changes:
- We now support all the ATMega-based Arduino boards, while still supporting the KL25Z. The KL25Z board is a better choice for a new user, since it is cheaper and has a much better analog-to-digital converter than the Arduinos, but there are a lot of Arduinos and Arduino clones already in hobbyist hands, and PteroDAQ now works for them with no new hardware.
- Sampling rates have improved enormously, particularly for the KL25Z and the Leonardo Arduino boards, which have USB serial communication without the bottleneck of a UART, but even the UART-based Arduino boards have a decent throughput of 2600Hz for a single analog channel. Leonardo gets 5370Hz, and the KL25Z is limited by the Python program on the host—7.8kHz on the old Windows machines, almost 10kHz on my old MacBook Pro (buffer overflow in the operating system loses some packets after a million samples), and about 19kHz on my son’s Linux laptop (again starting to lose samples after about 1 million). That’s not fast enough for high-quality audio, but it would do for speech-quality audio. It’s a lot better than the old v0.1 PteroDAQ, which was much more limited by the host, having trouble getting even 180Hz on the old Windows machines.
For short stretches, PteroDAQ can run somewhat faster—I can get 15kHz for about 400,000 samples on my MacBook Pro, which is long enough for a lot of lab experiments. - We’ve removed the need for PySerial. My son reimplemented the USB serial interface (based heavily on the PySerial implementation), so that we could have everything in a single download with no dependencies outside the standard modules that come with Python. The implementation may still be a bit inefficient (like the PySerial one), and we are considering working on it.
- Sparklines for the different signals now scroll smoothly even at the highest sampling rates, without taking up much of the host processor.
- Most recent data for each channel is shown numerically next to the channel (which is particularly useful when doing single samples).
- Resizing the window now works well, shrinking and stretching in the appropriate places.
- The GUI now reports errors when PteroDAQ can’t keep up with the requested sampling rate, which makes trading off the sampling rate and averaging easier.
The speed limitations are partly in how fast the Python program on the host machine can accept and process the data, and partly in how fast the KL25Z or Arduino board can do the analog-to-digital conversion. The Arduino boards hit the conversion limits before any of the host machines we used ran into Python limitations, but the KL25Z board with 1× averaging can produce data faster than any of our machines can accept it, so there is still work to be done on improving the efficiency of the Python code.
The software now needs a few users to test it out and find out what problems remain. Some things we won’t be able to do anything about—if Python crashes or the operating system messes up the communication link, there isn’t a lot we can do. Some things are not worth our time (like internationalizing the interface—though we do plan to get unicode characters properly handled in the Notes field—getting that to work in both Python2 and Python3 may be a bit tricky).
I encourage any one who has an Arduino or KL25Z board to try out the new system and tell what problems they have (other than the dire lack of documentation, which I will try to work on with my son over the summer). Ideas for new features are welcome also, though probably won’t come soon.
The software was a complete refactoring of the previous code, with much cleaner interfaces between the modules, which should help with maintenance and extension in future. I have a huge wish list for new features to add to PteroDAQ, but my son needs to get back to work on the new product for Futuristic Lights, and I need get back to work on my book, so I’ll mainly be putting ideas onto the issue tracker, with the intent of getting back to them later.
Filed under: Circuits course, Data acquisition Tagged: Arduino, data acquisition, KL25Z, PteroDAQ, sampling frequency